Creating Parquet Datasets with Squid SDK

In this article, we will delve deeper into the process of creating Parquet datasets using the Squid SDK. Parquet is a highly efficient columnar storage file format widely used for big data analytics. Its features, such as columnar storage, compression capabilities, and cross-platform compatibility, make it an excellent choice for processing and analyzing large datasets.
Parquet is a columnar storage file format designed for efficient data storage and processing in big data systems. The Parquet format has several key features that make it popular for big data analytics:
- Columnar Storage: Parquet stores data in a columnar format, which means that values from the same column are stored together. This design allows for efficient compression and encoding techniques that can significantly reduce storage space and improve query performance.
- Compression: Parquet supports various compression algorithms, such as Snappy, Gzip, and LZO. By compressing data at the column level, it can achieve higher compression ratios compared to row-based storage formats.
- Cross-Platform Compatibility: Parquet files can be read and written by multiple programming languages and frameworks, including Java, Python, R, and more. This makes it easy to integrate Parquet into existing data processing pipelines.
- And most importantly, parquet can be easily transformed into a Python dataframe and used together with numpy and other Python modules for data analysis.
To begin, let’s explore the steps involved in transforming a Squid into a Parquet dataset. Suppose we have a Squid that indexes all contracts, and we want to save the data into an S3 bucket in Parquet format. Unlike subgraphs, a Squid’s storage is configurable, which makes it easy to adapt. Instead of using Typeorm storage, we can import the file storage package and create a table to pass to the processor.
Let’s examine the default configuration, where the Squid uses Postgres as storage.

The processor utilizes the Typeorm database as storage, applies a schema, and saves items accordingly.
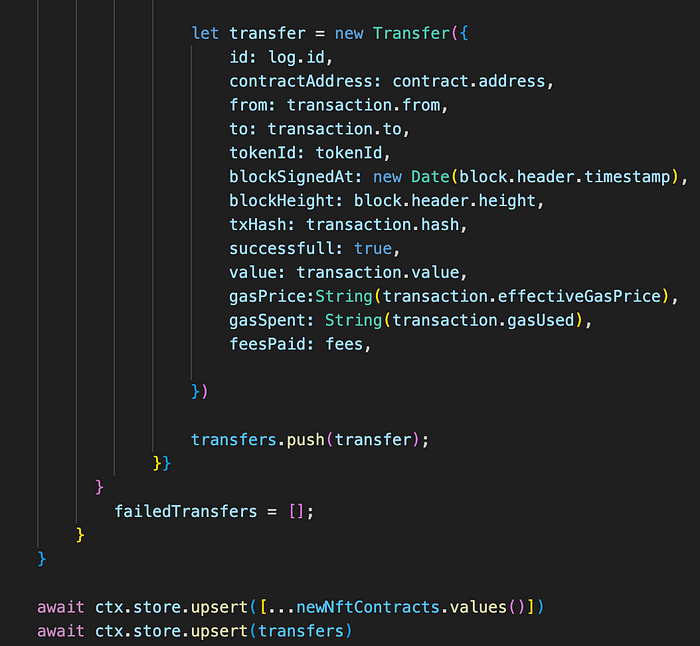
To covert this squid to use an S3 bucket and parquet format we need to do 3 simple steps.
Firstly, we import the necessary packages provided by the Squid SDK. These packages facilitate working with Parquet files and S3 buckets.

Secondly, we utilize the GraphQL schema already defined and translate it into a table with appropriate column types. This step ensures that the Parquet file maintains the desired structure.
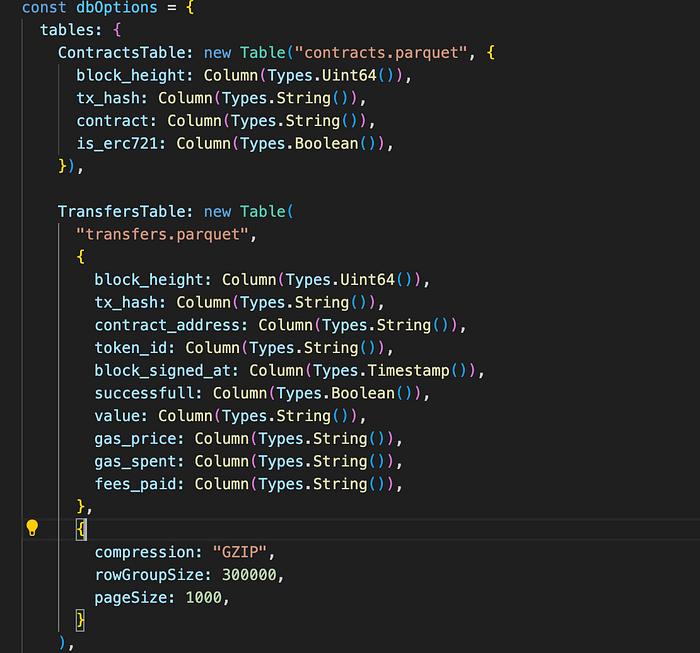
Finally, we modify the data-saving logic to save the data in the Parquet format. The Parquet filestore supports batch saving, so the process remains similar to before. This change ensures efficient storage and retrieval of blockchain data in the Parquet format.
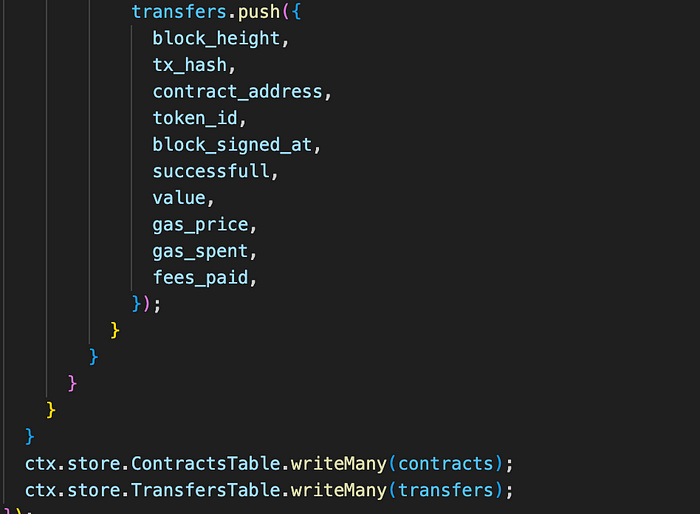
As another example, let’s consider another Squid that tracks all contract deployments.

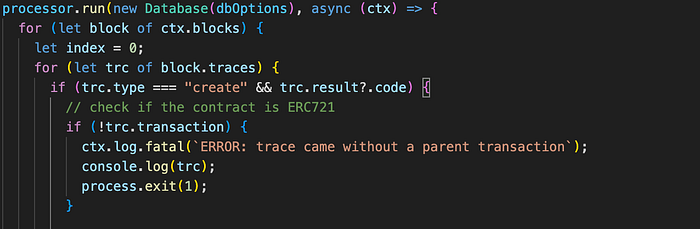

In this case, all deployments are saved in the “contracts.parquet” format based on their block number. Once the Parquet datasets are created, accessing the data becomes convenient.
Using the AWS SDK, we can list and read objects from the S3 bucket that stores the Parquet files. Alternatively, DuckDB can be used to query the Parquet table efficiently.

Given that Python is commonly used in data analytics, we decided to create Python notebooks to make the data interactive. We utilize the boto3 library to download the Parquet tables from the S3 bucket. Here is an example of how you can list all objects from a specific file:

Additionally, transforming a Parquet table into a dataframe is as simple as casting it. This allows seamless integration with popular Python libraries such as numpy for data analysis and manipulation.
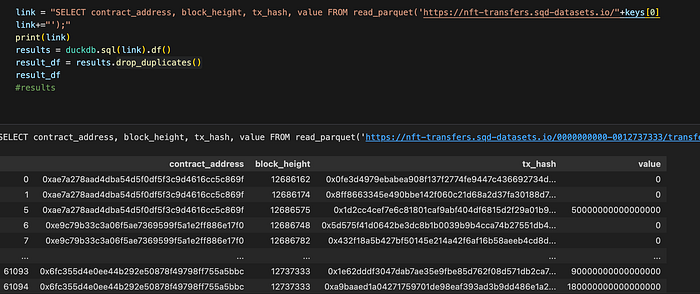
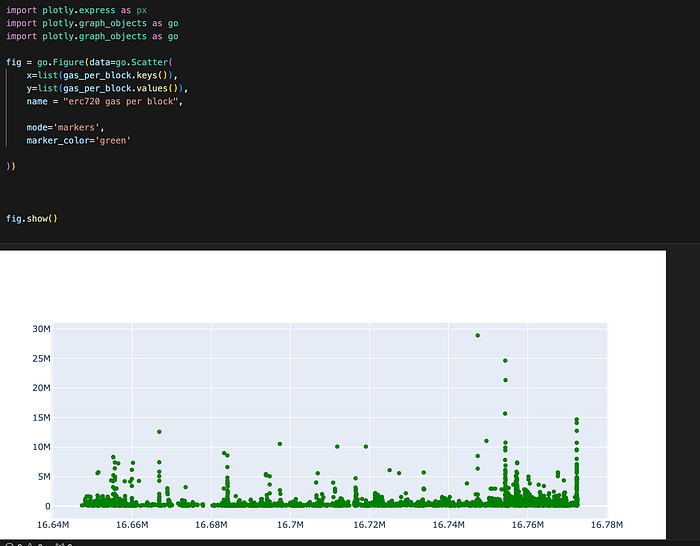
Once the data is preprocessed, various Python libraries can be utilized to create plots and visualizations. For instance, the plotly library can be used to plot the gas spent per block by NFT transfer transactions over a specific block range.
Jupiter notebooks are available here to experiment with.
You can also check out this squid, that saves all nft transfers to a postgres database. And here is an example of using parquet format in a simple squid and saving files locally.
To sum up, leveraging the Squid SDK and the Parquet format provides a powerful solution for indexing blockchain data and transforming it into efficient and easily accessible datasets. Parquet’s columnar storage, compression capabilities, and cross-platform compatibility make it an ideal choice for big data analytics.
By utilizing the Squid SDK, we were able to seamlessly transition from using a traditional storage method to leveraging S3 buckets and Parquet files. This change allowed us to take advantage of Parquet’s benefits, such as improved storage efficiency and query performance.
Accessing the Parquet datasets became straightforward using AWS SDK or tools like DuckDB for querying. Additionally, by incorporating Python notebooks, we enabled data analysts to interact with the data, perform preprocessing, and utilize popular libraries like plotly for visualizations.
Overall, the combination of Squid SDK, Parquet format, and Python notebooks empowers data analytics teams to efficiently process, analyze, and visualize blockchain data, providing valuable insights and enabling informed decision-making.